

Test-Driven Networks with pyATS
Look, NetDevOps is one of those terms that gets thrown around way too much at conferences. Half the time it’s just vendors trying to sell you something by sticking “DevOps” on the end of network automation. But there’s actually something useful buried in there if you can get past all the marketing rubbish.
Visit Blog post 1
45 blog post index
I remember when I first heard about test-driven networks. Thought it was just another buzzword. Then I saw what happened when a customer deployed changes without proper testing – three hours of downtime because nobody checked if the new OSPF configuration actually worked. That’s when it clicked for me.
Test-driven networks aren’t about fancy tools or complicated processes. They’re about not looking like an idiot when your changes break everything.
What NetDevOps Actually Means
Forget what the vendors tell you. NetDevOps is just taking the bits that work in software development and applying them to networks. Most engineers mess this up because they focus on buying tools instead of changing how they work.
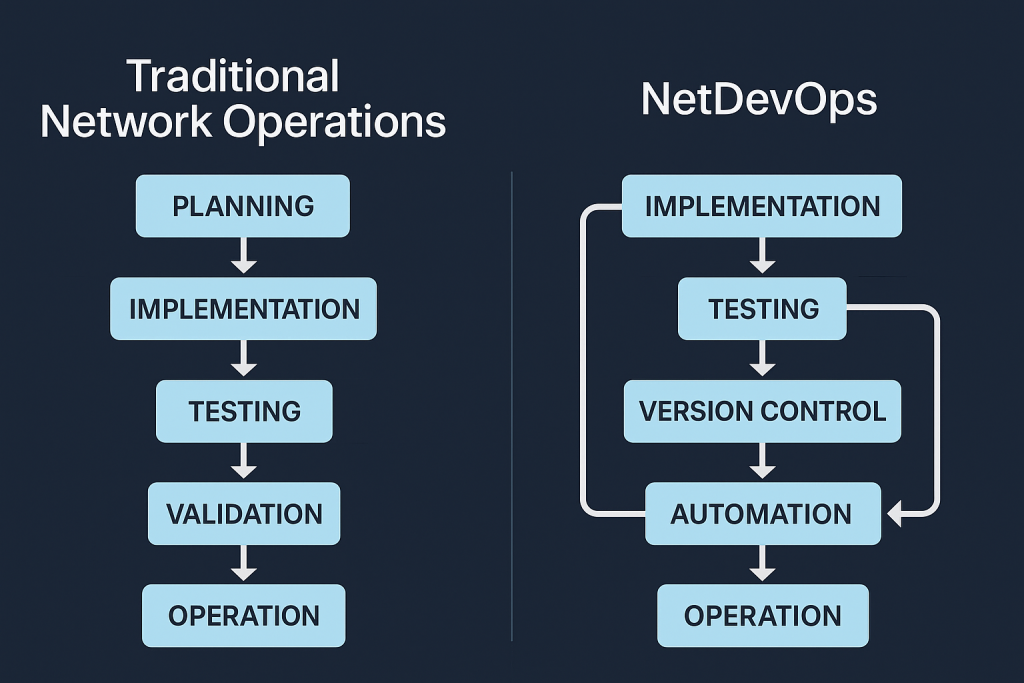
Here’s what actually matters:
Everything Goes in Git Your configs, scripts, documentation – everything. Not just backups, but proper version control. I’ve walked into networks where they tracked changes in Excel spreadsheets. Don’t be that person.
Test Before You Break Things Before you touch production, test it. Not just “ping and pray” but actual systematic testing.
# This is what a basic test looks like - don't worry about the details yet
from pyats import aetest
class TestConnectivity(aetest.Testcase):
@aetest.test
def test_interface_status(self, testbed):
device = testbed.devices['router1']
device.connect()
interfaces = device.parse('show interfaces')
critical_interfaces = ['GigabitEthernet1', 'GigabitEthernet2']
for interface in critical_interfaces:
status = interfaces[interface]['line_protocol_status']
assert status == 'up', f"Interface {interface} is {status}"
That’s pyATS checking your interfaces automatically. Instead of logging into each device and running show commands yourself, the test does it and tells you if something’s wrong.
No More Cowboy Changes Every change goes through a proper process. Review, test, deploy. No more “quick fixes” at 3 AM that break everything.
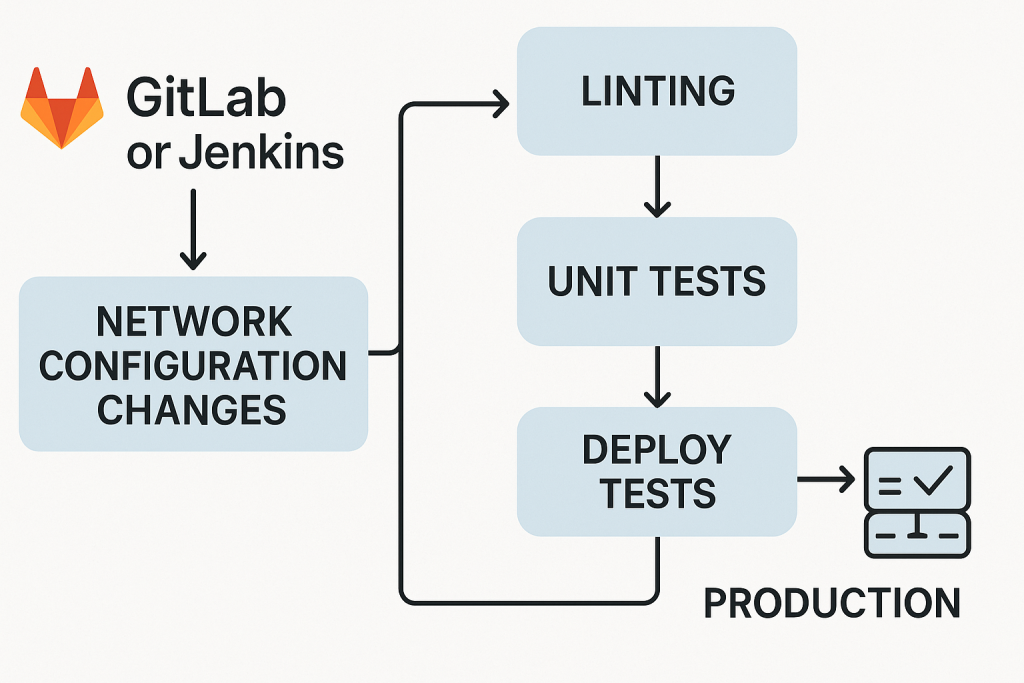
How Test-Driven Networks Work in Real Life
I worked with a retail company that had about 800 stores. Every time they made routing changes at head office, they’d spend the next week taking angry calls from store managers whose tills couldn’t process payments.
They had no way to check if changes worked across all stores. Just deploy and hope.
We built them test-driven networks that checked every store every 15 minutes:
- Can the store reach the internet?
- Can it talk to head office?
- Are the routing protocols working?
Now when they make changes, they know within minutes if any stores have problems. Fix them before anyone notices.
The tests were dead simple:
- Ping 8.8.8.8 from each store
- Ping the head office gateway
- Check OSPF neighbours are up
Nothing fancy. Just automated checking of the basics that matter.
What You Actually Test
Don’t just ping things and call it test-driven networks. You need to check multiple layers:
Basic Connectivity Can devices reach what they need to reach? But not just ping – check the applications actually work.
Protocol Status OSPF neighbours, BGP sessions, spanning tree – all the protocols that keep your network running.
Performance Latency, packet loss, throughput. Catch performance problems before users complain.
Configuration Compliance Every device configured according to your standards. No surprises six months later when you discover someone turned off security features.
Real Examples That Actually Worked
Bank Network Compliance
Had a bank that needed to prove their network met compliance requirements. Hundreds of branches, all with specific security rules.
We built tests that checked everything automatically:
- Branch connectivity to head office
- MPLS VPN working properly
- Security policies applied correctly
- QoS configured right
Tests ran every hour. When auditors showed up, we had months of reports proving everything was compliant.
Here’s a simple QoS check we did:
def check_qos_policy(device, interface):
qos_info = device.parse(f'show policy-map interface {interface}')
if not qos_info:
return False, "No QoS policy found"
if 'VOICE' in str(qos_info) and 'priority' in str(qos_info):
return True, "QoS looks good"
else:
return False, "Voice priority missing"
Instead of manually checking QoS on hundreds of devices, the tests did it automatically and flagged anything wrong.
Each branch needed consistent QoS config:
! IOS-XE QoS for branches
policy-map BRANCH_QOS
class VOICE
priority percent 30
class VIDEO
bandwidth percent 20
class DATA
bandwidth percent 40
class class-default
bandwidth percent 10
interface GigabitEthernet1
service-policy output BRANCH_QOS
! IOS-XR version
policy-map BRANCH_QOS
class VOICE
priority level 1
police rate percent 30
class VIDEO
bandwidth percent 20
class DATA
bandwidth percent 40
class class-default
bandwidth percent 10
interface GigabitEthernet0/0/0/1
service-policy output BRANCH_QOS
Manufacturing Network That Couldn’t Go Down
Manufacturing company with production systems that couldn’t tolerate downtime. Needed to know failover would work without actually testing it and breaking production.
Test-driven networks checked:
- Backup routes exist in routing table
- Backup interfaces are up and ready
- Spanning tree has proper backup ports
- Failover times meet requirements
When a link actually failed, everything failed over in under 200ms. Without the tests, they’d never have known if failover worked until they needed it.
ISP Customer Validation
ISP with thousands of customers. Can’t manually check every connection.
Tests validated each customer automatically:
- BGP sessions established
- QoS policies applied
- Bandwidth limits enforced
Tests ran every 30 minutes for critical customers. When problems were found, tickets got created automatically with all the diagnostic info needed.
Found problems before customers rang to complain.

Getting Started Without Going Mad
Don’t try to test everything on day one. Start small.
Pick your most critical paths:
- Internet connectivity from data centres
- Connectivity between main sites
- Access to important applications
Build simple tests:
- Can data centre reach internet?
- Can branches reach data centre?
- Can users reach application servers?
Basic ping tests catch most problems and give you confidence.
Mistakes Everyone Makes
Testing Everything Every Minute Don’t do this. You’ll overwhelm your monitoring and create more noise than signal.
Think about what needs frequent checking:
- Interface status: every 5 minutes
- Routing protocols: every 15 minutes
- Performance tests: every few hours
Testing everything constantly just creates problems.
Tests That Don’t Actually Test Anything I’ve seen companies that pinged devices every few minutes and thought they had test-driven networks. When DNS failed, tests kept passing because devices were reachable, but users couldn’t access anything.
Make sure your tests actually validate what matters.
Ignoring the Results Tests are useless if you don’t act on them. Use the data to fix problems before they affect users.

Tools You Actually Need
You don’t need expensive commercial tools. Open source works fine for most things.
pyATS for Network Testing Built specifically for network testing. Can connect to multiple vendors, parse output into usable data, compare network state over time, generate proper reports.
Integration with Monitoring Tests should integrate with your existing monitoring. When tests fail, alerts get generated with enough context to actually fix the problem.
Version Control All test code goes in Git. Changes to tests get reviewed like changes to network configs.
How to Know It’s Working
Track these numbers:
Mean Time to Detection How fast do you spot problems? Should be minutes, not hours.
Mean Time to Resolution How fast can you fix things? Good tests provide enough info to speed up troubleshooting.
Change Success Rate What percentage of changes work first time? Should improve dramatically.
Unplanned Downtime How often do users get surprised by network problems? Should be rare.
Working with Automation
Test-driven networks and automation work together. Automation does the repetitive stuff, tests validate it worked.
When automation deploys new branch office config, tests verify:
- Devices are reachable
- Routing protocols work
- Security policies applied
- Applications connect properly
Without testing, automation can break things faster than humans ever could.
The Culture Bit
This isn’t just about tools. You need to change how your team thinks.
Proactive Instead of Reactive Traditional networking is firefighting. Something breaks, you fix it. Test-driven networks are fire prevention.
Failure is Information Tests will find problems. Don’t shoot the messenger. Use failures to improve your network.
Use the Data Tests generate tons of data about network behaviour. Use it to make better decisions about capacity, architecture, operations.
Advanced Stuff for Later
Once you’ve got basics working:
Chaos Engineering Deliberately break things to test resilience. Sounds scary but controlled failure testing is safer than discovering problems during real outages.
Predictive Testing Use historical data to predict when problems might occur.
Intent-Based Networking Define what you want the network to do, then test that it actually does it.
Start Tomorrow
Don’t wait for perfect solution:
- Pick one critical path
- Write simple test to validate it works
- Run test regularly
- Expand gradually
Start with single test. Once you see value, you’ll want to test everything.
Test-driven networks change how you think about networking. Instead of hoping things work, you know they work because you test continuously. Instead of reacting to problems, you prevent them.
Users expect reliable networks. Business expects predictable operations. Test-driven networks deliver both while making your job less stressful.
Won’t happen overnight, but every step makes your job easier and network more reliable.
Next post we’ll look at pyATS ecosystem and how all the pieces fit together. You’ll see the architecture that makes pyATS powerful for network testing.
Learn more about network automation best practices at Cisco DevNet
Totally agree that ‘NetDevOps’ often gets lost in the hype. Your point about putting everything in Git and actually testing before pushing to production really hits home—especially after seeing outages caused by untested changes. It’s refreshing to see a practical take that focuses more on mindset than tools.
Pingback: Blog Index: Cisco pyATS Automation - RichardKilleen